Let x1, …, xn be given, where they are all some real numbers. Define the following function:
resimdeki fonksiyon
img527.imageshack.us
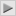
Can you find an expression for y* which minimizes g(y) in terms of x1, …, xn? What are the difficulties you encounter in this process? Do you think there may be alternative minimizers (alternative optima) for g? Can you claim that the sample mean, , is a minimizer of g? Why or why not? Explain. Note that you do not need to find y*, only think about how you can find it if necessary.
Yardımcı olursanız çok sevinirim ipucu olabilecek herhangi birşeyler de yazsanız olur.Teşekkürler
Birinci kısmı için konuşuyorum:
Deviasyon sonuçta sizin elinizdeki datanın ortalamadan ne kadar uzaklaştığının bir hesabı. yani şöyle bir örnek vereyim elinizde 1 1 3 5 5 7 1 2 2 gibi bir veri var, bunun averajı (ortalaması, meani) 3. siz elinizdeki verilerin genel anlamda 3'ten ne kadar uzaklaştığını bulmaya çalışıyorsunuz. Bunu yapmak için her bir verinin 3'ten ne kadar uzaklaştığını bulup, bunları toplayıp, sonra da elimizdeki veri sayısına bölmemiz gayet mantıklıdır. Tek bir şey dışında. Şimdi önce bu dediğim şekilde yapalım.
[(1-3)+(1-3)+(3-3)+.....+(1-3)+(2-3)+(2-3)]/7
İşlemi böyle yaparsanız koca bir 0 bulursunuz, çünkü ortalamadan az olan verilerle, ortalamadan fazla olan veriler birbirlerini götürür. Oysaki deviasyon hem artı hem de eksi yönde olabilir. O nedenle bizim bu sapmayı bulmak için sadece çıkarma değil, çıkardıktan sonra kalan sayının mutlak değerini almamız gerekir.
Standard sapma hesabında mutlak değer yerine karesini alıp, sonra her şey bittikten sonra karekök almamızın nedeni de bu zaten.
Şİmdi çıkmam gerekiyor, o yüzden ikinci kısma bakamadım.


zannedersem sayin sui soruda ne istendigini anlamamis. neden mutlak deger almiyoruz da , karelerinin toplaminin karekokunu aliyoruz denmis. mutlak degerlerini toplarsaniz, sonuc 0 cikmaz zaten.
soruya donecek olursak, ben de arastirmistim bunun nedenini ama buldugum cevap, hassasligin arttirmak icin bu islemin uygulandigiydi. ama bence bu yeterli bir aciklama degil; o yuzden cevap -bana gore - soyle olmali:
elimizde n tane data oldugunu ve bu datalarin n boyutlu bir uzayi olusturdugunu dusunursek, elimizdeki data setinin elemanlarini ortalamadan uzakligini bulmak icin , her birinin ortalamadan cikartip karelerinin toplaminin karekokunu almaliyiz.
daha basit anlatacak olursak, pisagor teoreminde hipotenusu bulmak icin ne yapiyorsakm , aynisini bu n boyutlu uzaydaki n vektore uyguluyoruz. mantik ayni.
2. sorun ise eger lagrange multiplier gorduysen, onunla ilgili olmali. zaten degiskenler arasindaki iliskiler verilmediginden pek birsey soyleyemeyecegim.
bir de bu ders istatistik mi, yoksa baska bir ders icin giris olarka mi goruyorsun?

Evet anlamamışım resmen. Aceleyle okurken neden mutlak değer alıyoruz diye algıladım ben onu :)
Neyse kusura bakmayın.